
FPGA INTEL otimizado para aceleração de AI de alta largura de banda e baixa latência

O processamento de linguagem natural (PNL, do inglês Natural Language Processing) é um subcampo da lingüística, ciência da computação, engenharia da informação e inteligência artificial relacionado às interações entre computadores e linguagens humanas (naturais), é como programar computadores para processar e analisar grandes quantidades de dados em linguagem natural.
Os desafios no processamento de linguagem natural freqüentemente envolvem reconhecimento de fala, compreensão de linguagem natural e geração de linguagem natural.
Aplicações deste tipo que requerem rápido processamneto de um grande número de dados podem ser implementadas utilizando FPGA’s e Inteligência Artificial (IA). E a Intel tem a solução certa para a sua aplicação.
O Intel® Stratix® 10 NX FPGA oferece uma combinação única de recursos necessários para implementar hardware personalizado com inteligência artificial (AI) de alto desempenho integrada. Esses recursos incluem:
- Blocos de tensores AI de alto desempenho
- Até 15X mais desempenho de computação INT8 do que o bloco de processamento digital de sinal (DSP) Intel Stratix 10 FPGA para cargas de trabalho de IA
- Hardware programável para IA com cargas de trabalho personalizadas
- Abundante Near-Compute Memória
- Hierarquia de memória incorporada e personalizável para persistência do modelo
- Memória integrada de alta largura de banda (HBM)
- Rede de alta largura de banda
- Transceptores PAM4 de até 57,8 G e blocos hard Ethernet para alta eficiência
- Interconexão flexível e personalizável para escalonar em vários nós
Esses três conjuntos de recursos permitem que os FPGAs Intel Stratix 10 NX atendam exclusivamente à tendência de baixa latência e modelos de IA maiores, exigindo maior densidade de computação, largura de banda da memória e escalabilidade em vários nós, além de funções personalizadas reconfiguráveis.
Apresentando o AI Tensor Block: ativando a densidade de computação inovadora
O FPGA Intel Stratix 10 NX inclui novos tipos de blocos aritméticos de tensores otimizados para IA, chamados de AI Tensor Blocks. Esses blocos contêm uma matriz densa ou multiplicadores de menor precisão, normalmente usados em aplicativos de IA. A arquitetura do AI Tensor Block é ajustada para multiplicações matriz-matriz ou vetor-matriz usadas em uma ampla gama de cálculos de IA com recursos projetados para trabalhar eficientemente para tamanhos de matrizes pequenas e grandes.
Diagrama de alto nível do AI Tensor Block:
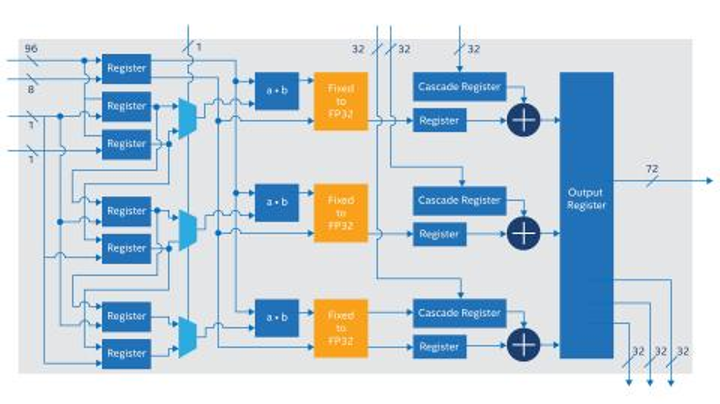
Os multiplicadores AI Tensor Block têm precisões básicas de INT8 e INT4 e suportam formatos numéricos FP16 e FP12 por meio de hardware de suporte de expoente compartilhado. Todas as adições ou acumulações podem ser realizadas com a precisão de ponto flutuante de precisão simples (FP32) INT32 ou IEEE754 e blocos AI Tensor Block podem ser conectados em cascata para suportar matrizes maiores. Estima-se que um único bloco tensor de AI alcance até 15 vezes mais processamento INT8 quando comparado ao bloco DSP padrão Intel Stratix 10 FPGA.
Aplicações:
Processamento de linguagem natural
- Reconhecimento de fala
- Síntese de fala
Segurança
- Inspeção profunda de pacotes
- Identificação de controle de congestionamento
- Detecção de fraude
Análise de vídeo em tempo real
- Reconhecimento de conteúdo
- Pré e pós-processamento de vídeo